
A lot of SEO experts argue that sentiment is an important ranking factor that Google uses to determine if a page should rank in the serp results. If you want to rank for a keyword and all the results have a positive sentiment then you must follow the trend and ensure that your content contain positive sentiment.
We have analysed over 60K pages from the gambling, technology and financial industries (sector) and this article documents the steps we took to analyse the content and generate insights on whether content sentiment has any influence on ranking. (changed quite a bit)
Is it true that sentiment is a ranking factor in Google searches? Read on.
Sentiment Analysis with Python Step-by-step process
The following analysis is aimed at investigating the link between webpage sentiment and their ranking on Google, in the context of the sentiment of the search query. For this task we will be using Python’s TextBlob library. TextBlob is free to use, can be called locally with reasonable efficiency and requires little to no pre-processing . This library is perfect for this investigation as it will allow us to write up our sentiment analysis code quickly and efficiently, providing us with the much sought-after results within a matter of hours.
Here is a brief list of TextBlob’s main highlights:
- It can determine whether the opinion or feeling expressed in a text is positive, neutral, or negative.
- Similarly, it is also capable of accurately tagging the parts of speech.
- It can split any block or document of text into words and sentences.
- Can collect n-grams from a given text corpus.
- Detect spelling mistakes and correct them if needed.
- Supports multiple languages
For this investigation we shall make use of its sentiment analysis function, TextBlob.sentiment, which returns two values: sentiment polarity and sentiment subjectivity. The former indicates whether the sentiment expressed in the input text is negative or positive (ranging between -1 and 1) and the latter indicates how subjective the input text is (ranging between 0 and 1). You may learn about the mathematical calculation behind these values here.
Dataset and Coding in Python
In order to investigate the link between content quality and Google ranking we compiled a table of 6,000 search queries related to the Financial Services, Online Gambling and Technology industries. That is, for each industry we scraped 2,000 search queries which contained keywords related to this industry.
The first dataset, which was stored in XLTM format, was imported into a pandas DataFrame in Python using the code shown in Figure 1. We also added two columns named Polarity, in which we shall store the TextBlob Polarity score for each query, and Subjectivity, in which we shall store the TextBlob Subjectivity score for each query. We also typecast the query column to a string data type to ensure compatibility with the TextBlob library functions.
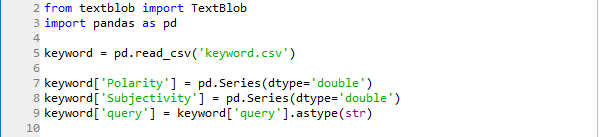
Figure 1: Importing the TextBlob library, reading the ‘keyword’ DataFrame and adding columns
The first 10 records of our keyword DataFrame are shown in Figure 2, in which the Index column is assigned by pandas, the id column refers to a unique id for each query, the query columns contains the individual queries, the type column contains the industry type (1 = Technology, 2 = Online Gambling, 3 = Financial Services).
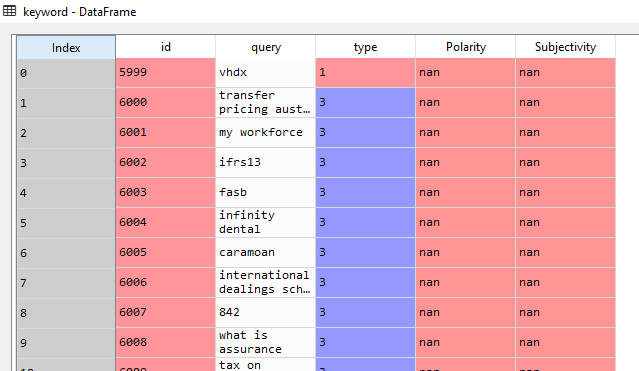
Figure 2: The first 10 records of the keyword DataFrame
We then compiled a separate table named page, also in csv format, containing the top 10 links following each query. This was also loaded into a Python pandas DataFrame using the code shown in Figure 3.
![]()
Figure 3: Reading the page csv file as a DataFrame
The first 10 records of our page DataFrame are shown in Figure 4, in which the Index column is assigned by pandas, the id column refers to a unique identifier for each search result, the position column refers to the ranking of the search result, the url column refers to the search result url, the text refers to the article text contained within the url page, the title refers to the title of the article, the h1 column refers to the HTML tag, the metadescription column refers to the meta tag, the keyword column refers to the keyword ID from the keyword DataFrame. This is the identifier that links our two DataFrames together.
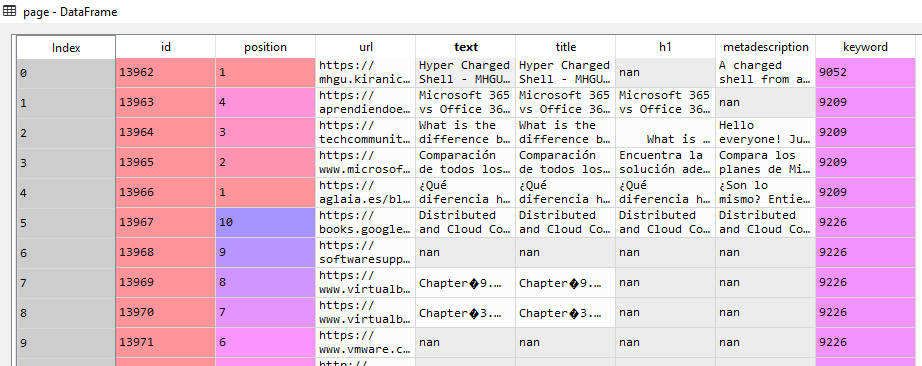
Figure 4: The first 10 records of the page DataFrame
As part of our data pre-processing we type cast the text, title, h1 and metadescription columns to string data type to ensure compatibility with TextBlob. For each of these columns we added a Polarity column and a Subjectivity column to store the TextBlob polarity and subjectivity scores for the text, title, h1 and metadescription columns, as shown in Figure 5.
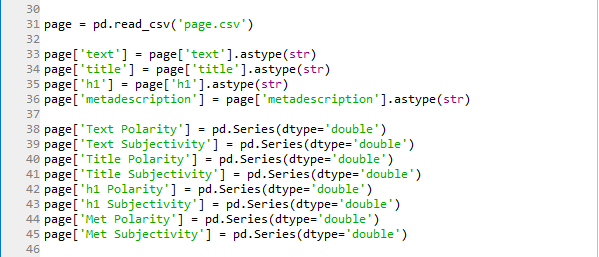
Figure 5: Simple data pre-processing on the page DataFrame and adding columns
The corresponding first 10 rows for the resultant columns are shown in Figure 6.
Figure 6: The first 10 records of the additional columns in the page DataFrame
Now that our datasets are ready, it is time to perform some sentiment analysis. This can be performed easily by calling the TextBlob.sentiment function and assigning the output to the variable sentiment (for each row in the keyword DataFrame) as shown in Figure 7. The sentiment polarity is stored under sentiment.polarity and the sentiment subjectivity is stored under sentiment.subjectivity. The output values of the TextBlob function are stored under the columns Polarity and Sentiment. To avoid our code breaking due to any errors that the TextBlob.sentiment function may produce, we used try and except blocks as shown in Figure 7.

Figure 7: Query sentiment polarity and subjectivity analysis using TextBlob whilst ensuring our code does not break due to any errors using try and except blocks.
The sentiment analysis for the the text, title, h1 and metadescription of the corresponding top 10 search results were performed in the same way and the results were stored in their respective columns. As an example, the code used to analyse the sentiment of the page text is shown in Figure 8.

Figure 8: Page text sentiment polarity and subjectivity analysis using TextBlob whilst ensuring our code does not break due to any errors using try and except blocks.
Now that we have performed sentiment analysis on our two DataFrames (or tables), we must save our new appended DataFrames as CSV files to allow further analysis using other tools. This is done using the code shown in Figure 9.

Figure 9: Saving our appended DataFrames as CSV files
We now possess two tables containing the sentiment polarity and subjectivity for queries and their related search results.
Analysis of Results in Microsoft Power BI
We loaded our CSV files into Microsoft Power BI to create some interesting visualizations which will allow us to further investigate the possible relationship between sentiment and Google ranking. You may access our dashboard via this link, in which you shall be able to play around with the variables, in the interim here is an interesting summary of the results.
First let us have a look at the link between sentiment polarity which could range from negative sentiment (-1), neutral sentiment (0), positive sentiment (1) and anything in between these values.
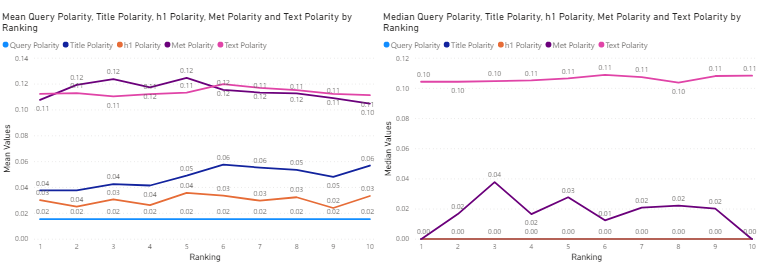
Figure 10: All industries – mean (left) and median (right) sentiment polarity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
Figure 10 exhibits the relationship between the mean (left) and median (right) sentiment polarity values of the search query (cyan), and the title (blue), h1 tag (orange), meta description (purple) and text (pink) for the top 10 Google search results related to this query for all three industries. Figure 11, 12 and 13 exhibit a drill-down of this relationship for the Financial Services industry, Online Gambling Industry, and the Technology Industry, respectively.
For both the mean and the median values it is evident that the sentiment polarity of the query is matched by the sentiment polarity of the h1 tag for all the top 10 results. In both cases, the magnitude of the polarity is extremely low, indicating that the sentiment is neutral. In the case of the title sentiment polarity, the mean value starts at a low value (positive but close to neutral) and slowly increases with the ranking. The median value for the title sentiment polarity is neutral for all the top 10 results. Both the mean and median meta-description and text sentiment polarity values start at low positive values and increase slowly but steadily as the ranking of the results increases. These results seem to support the hypothesis that Google prefers to return results with neutral or positive sentiment. They also indicate that a neutral query results in links with neutral titles and neutral h1 tags and low positive meta-description and text. As the ranking of a search result increases, so does its sentiment polarity.
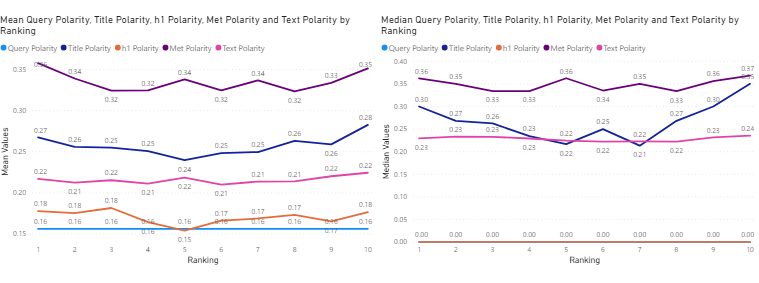
Figure 11: Financial Services Industry – mean (left) and median (right) sentiment polarity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
These results are not exactly emulated in each individual industry. For example, for the Financial Services industry (exhibited in Figure 11) both the median and mean sentiment polarity values remain low and neutral for all top 10 results, with the exception of the mean h1 and title sentiment polarity which increase ever so slightly as the ranking increases.
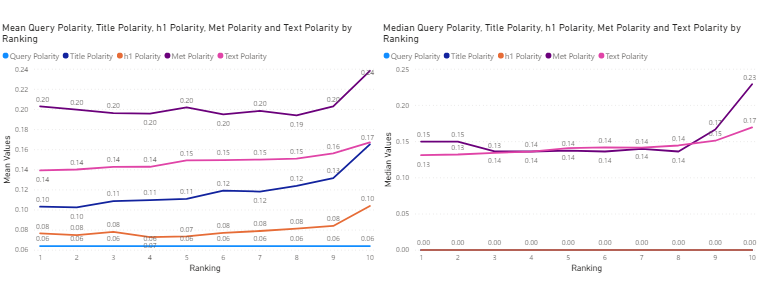
Figure 12: Online Gambling Industry – mean (left) and median (right) sentiment polarity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
In the Online Gambling industry, exhibited in Figure 12, both mean and median sentiment polarity does not seemingly increase with the ranking for neither of the content elements. However it is interesting that in this industry both the mean and median query sentiment polarity is positive and much higher than in other industries and is generally higher for all the webpage content elements. These findings support the hypothesis that positive sentiment query returns positive sentiment results. In fact, the sentiment polarity of the title, meta-description and text of the top 10 results is the highest amongst all industries and remains (Relatively) high for all top 10 results.
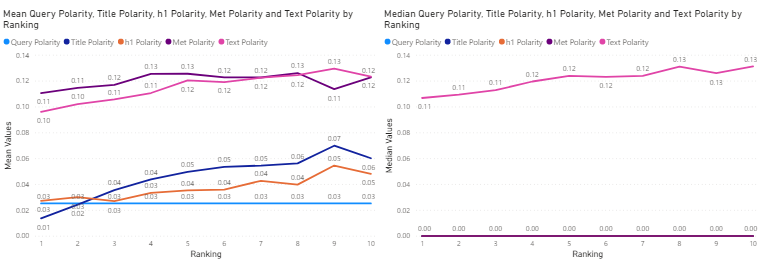
Figure 13:values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
In the technology industry, we see a repeat of the pattern shown by the graph for all three industries, in that the mean sentiment polarity for all values increases with the ranking in response to query sentiment polarity which remains low positive (almost neutral) for all the top 10 results.
In all examples, the mean and median sentiment polarity for all webpage content elements is always positive and very low, indicating that neutral or slightly positive sentiment is preferred for the top 10 results. The sentiment expressed in the search query is always matched by the sentiment query of the results.
We shall now have a look at the link between sentiment subjectivity which could range from objective (0) to highly subjective (1).
Figure 14 exhibits the relationship between the mean (left) and median (right) sentiment subjectivity values of the search query (cyan), and the title (blue), h1 tag (orange), meta description (purple) and text (pink) for the top 10 Google search results related to this query for all three industries. Figure 15, 16 and 17 exhibit a drill-down of this relationship for the Financial Services industry, Online Gambling Industry, and the Technology Industry, respectively.
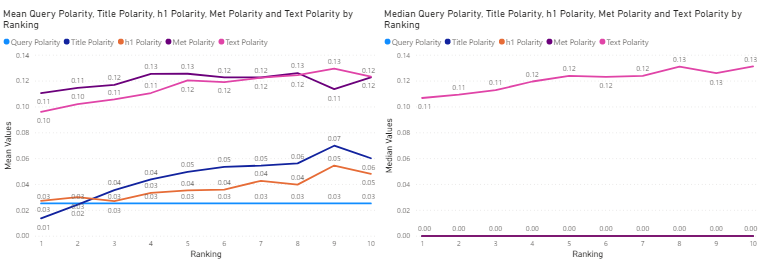
Figure 14: All industries – mean (left) and median (right) sentiment subjectivity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
In this case, a (relatively) objective query is matched by a (relatively) objective h1 tag since both subjectivity values are close to 0. In the case of the mean values, there seems to be a general trend in which results with lower rankings (the much sought after 1st, 2nd and 3rd spots on Google SERP) are more objective and become more subjective at higher rankings (the less appealing 9th and 10th spots). This is only reflected in the subjectivity of the text in the median value plot.
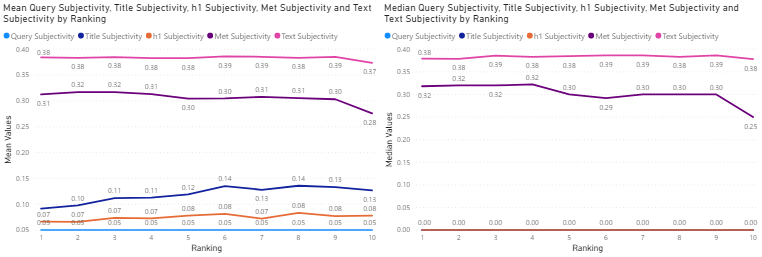
Figure 15: Financial Services Industry – mean (left) and median (right) sentiment subjectivity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
In the case of the Financial Services Industry, exhibited in Figure 15, an objective search query results in links which generally contain objective titles and h1 tag, but subjective text and meta-description.
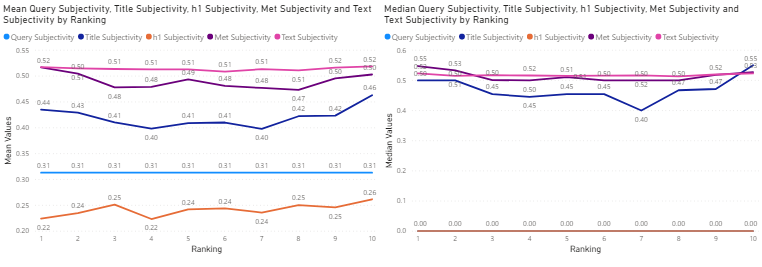
Figure 16: Online Gambling Industry – mean (left) and median (right) sentiment subjectivity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
The Online Gambling Industry is always an exception as shown in Figure 16. A subjective search query (mean value for search query) returns top 10 results which contain less subjective h1 tags (reflected also in the median graph), and highly subjective titles, meta-description and text. There is no evident pattern of a positive (or negative) relationship between the Google ranking of a webpage and the subjectivity of its content, however in the vast majority of cases the top 10 results have always contained highly subjective text.
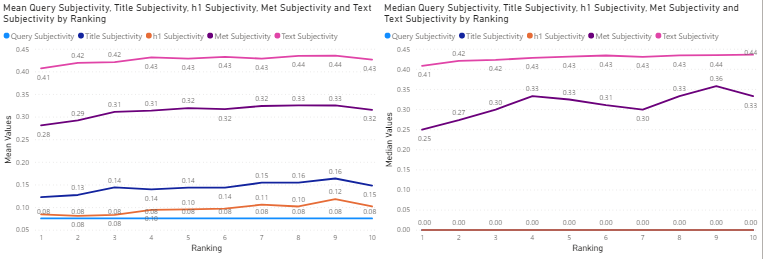
Figure 17: Technology Industry – mean (left) and median (right) sentiment subjectivity values of search query and title, h1, meta description and text for the top 10 corresponding search results, against ranking.
In the Technology Industry, whose data is shown in Figure 17, there seems to be a positive relationship between increased subjectivity and ranking. This is the case for both the mean and median data values, specifically for the text and meta-description. Webpages with less objective data seem to enjoy higher spots on Google SERP.
Our Conclusions
All in all the scope of this research exercise was a fruitful one as it allowed us to play allowed with one of Python’s most popular sentiment analysis libraries and gave us a real feel of what it would mean to implement this process as part of a large data-driven SEO approach that draws insights from sentiment analysis.
You may have a deeper look at our analysis results by visiting the following reports
Sentiment Analysis for Gambling
Sentiment Analysis for Finance Services
Sentiment Analysis for Technology
Sentiment Analysis all Industries
Following are the general findings from this analysis:
The h1 tag is always relatively both neutral and objective and increases with ranking in most cases. This finding could be a mere reflection of the other content on the webpage (most h1 tags are copy and paste versions of other tags/titles), however it definitely warrants further investigation into the relationship between the h1 tag and the ranking.
There were two scenarios for the title of a webpage: the title polarity and subjectivity either increased with ranking (this mostly occurred for the mean value analysis) or else remained low and constant throughout all top 10 results. Generally, the top three search results enjoyed more neutral and less subjective wording than their higher ranked counterparts.
The meta-description exhibited similar patterns, in which it either increased with ranking (both for polarity and sentiment) or remained constant (more or less) for all cases. Nonetheless, the polarity was always positive and relatively highly subjective. This was also the case for the webpage’s text. Google seemingly prefers to populate its top 3 results with webpages with text and titles which are positive and somewhat subjective. It is important not to overdo it however, as highly subjective and highly positive articles seemed to occupy higher spots (9th and 10th) on Google’s landing page.
In the context of each industry, the Online Gambling industry seems to always return positive and subjective results for all top 10 spots. There does not seem to be a general rule with regards to how these values vary, however since this is an entertainment industry, happy toned content with good reviews is preferred. In the Technology and Financial Services industries more objective and neutral content was generally preferred. In the former industry this was the case for all content type whilst in the latter industry this was the case for the title and h1 tag but not for the meta-description and text.
It is important to note that the query subjectivity is always matched by the results, specifically by the h1 tag. This definitely supports the popular hypothesis that Google uses its sentiment analysis to detect user search intent. In terms of results content, webpages containing negative sentiment did not feature in the top 10 spots in neither the mean or median analysis. Highly subjective content also did not feature in these spots. Therefore as a general take home message, it is important to create positive content which contains a human element but that is not highly opinionated and does contain some form of objectivity.

Dr Michaela Spiteri BEng, MSc, PhD (AI / Healthcare domain), is a well-published researcher in the field of AI and machine-learning. She is the founder of AI consultancy Analitigo Ltd. Currently working as the lead researcher at Gainchanger.
