
When we search on Google, we expect to retrieve the most relevant website related to our query. What if I had to tell you that there exists a search engine that can give you a detailed graph and tabulation analysis on the go? Or a search engine that can search through the historical timelines of websites? Here are the ultimate search engines you should use.
1. WolframAlpha
A fact search engine retrieving visually analytical results

WolframAlpha is a different search model for gathering information. Supported by Stephen Wolfram, a well-known scientist and author of A New Kind Of Science. It is a form of answer search engine that presents you with results in an analytical and visual way. This is where it is distinct from traditional search engines. Rather than matching the query terms by presenting websites, it offers direct answers inside the results.
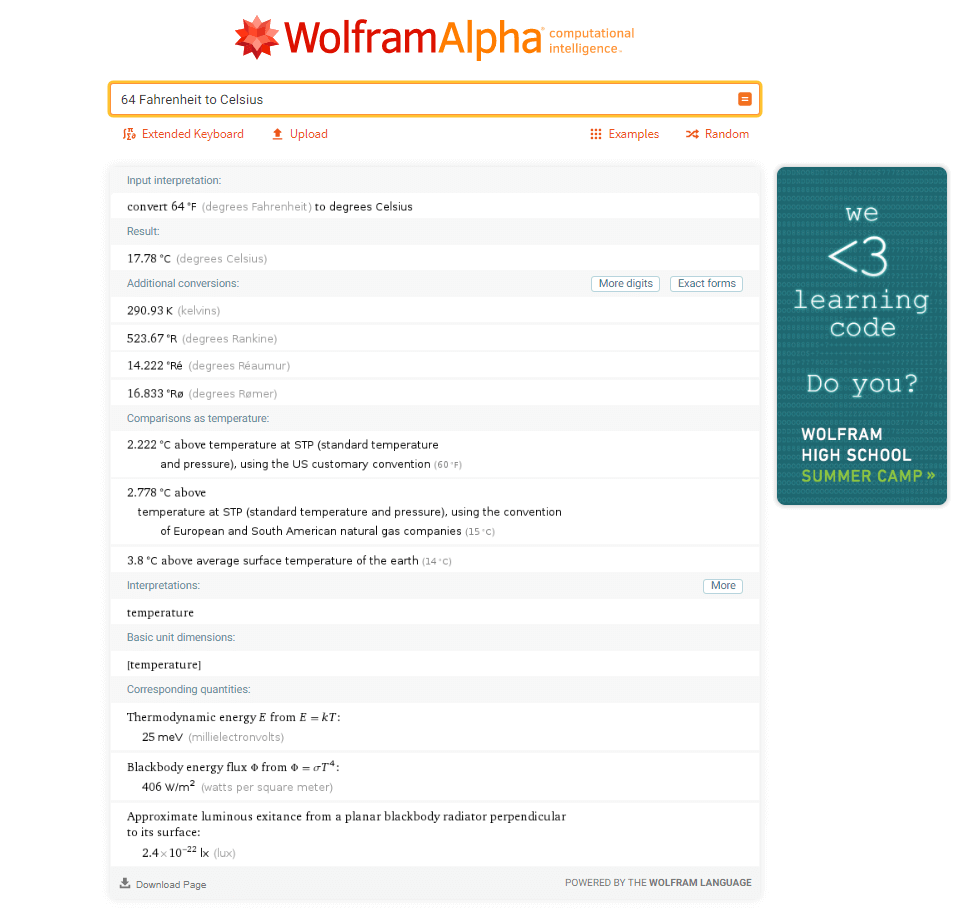
As you can see above, a query to convert Fahrenheit to Celcius displays a detailed outlook. It not only converts it on the fly, but it also provides you with more information such as different conversions, equations using the units, and descriptions of the temperature itself.
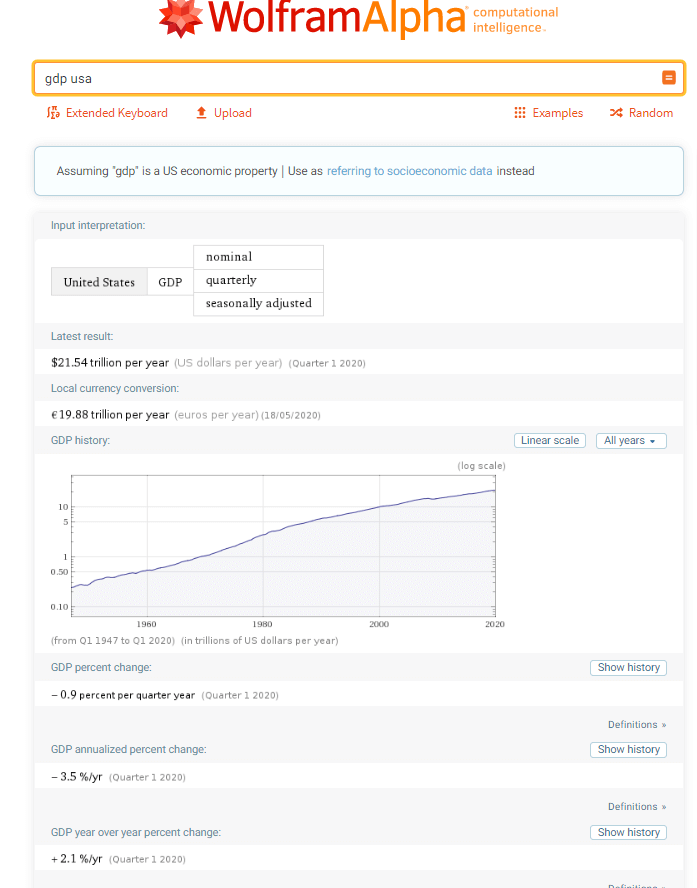
Statistical results
A search to determine the GDP for the USA, for instance, will give you a timescale of the GDP history and currency conversion, as well as other information. Note that each category can be expanded further or adapted. So, as you can see each query will yield extended visual and analytical information and it does it relatively fast. At the bottom of the search results, it also provides related search terms that can help you widen your search.
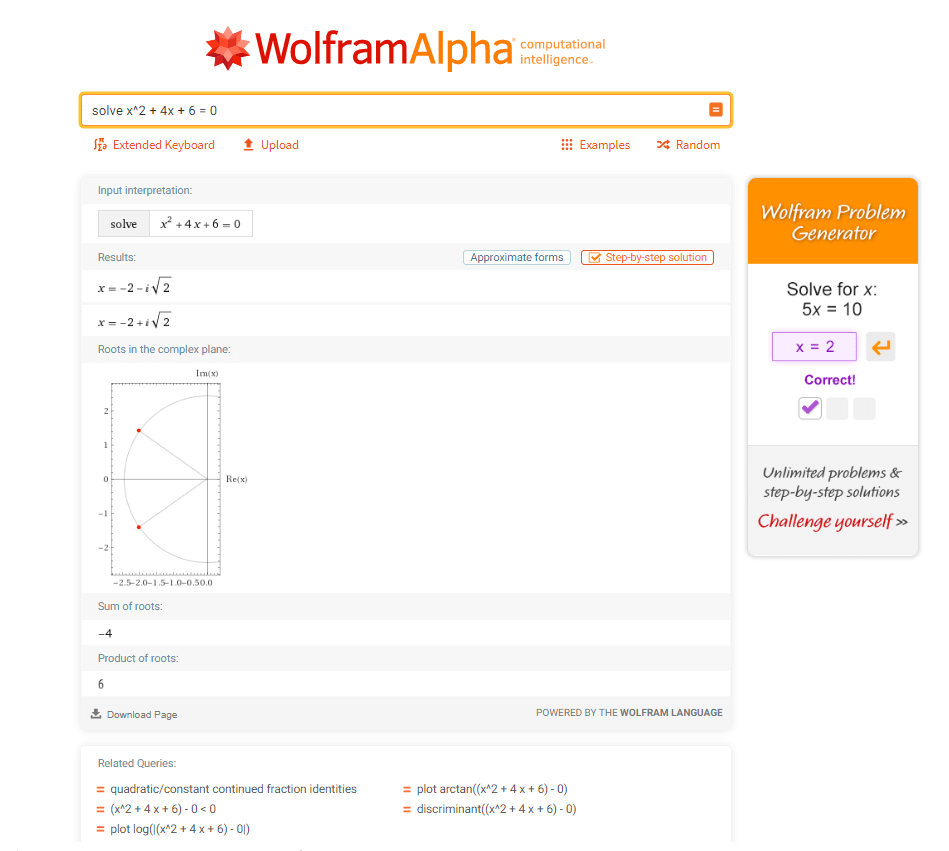
A different form of queries
Another impressive feature is searching by equations. WolframAlpha is able to solve your algebraic and calculus equations or any physics formulae. In fact, it is capable of searching through a lot of scientific databases to provide you with information for all branches of science including chemistry, biology, engineering and statistics. Apart from this, it also delves into social studies such as politics, arts and history.
Source of information
So, one might ask, what’s the source of all this information? Rather than crawling the web, it extracts information from a variety of providers to consolidate public and private information. Such providers include government agencies, universities and other organizations.
Classification of queries into data sets
WolframAlpha uses classification systems to determine the semantics behind the user query and what data set to use in the results. For example, if one searches for ‘Puma’, it makes certain assumptions that the user is searching for the Puma sports company and not the animal. Data sets are not mixed in the results.
2. DuckDuckGo
Privacy is their priority; Dynamic vertical search

Privacy
Privacy is something we have taken for granted. We have accepted that search engines will give us the needed information at the cost of storing our information. Except, it doesn’t need to be that way. DuckDuckGo strives to do the exact opposite. It claims to not store or share any form of data. It doesn’t show any ads pertaining to your search history, won’t track location and won’t sell any personal data despite not being in incognito mode. This makes the search engine above the rest in terms of respect for privacy.
Dynamic Vertical-search and multiple search sources
Apart from privacy, it also has a unique characteristic in that it uses multiple sources to extract the information needed. It uses Yandex, Yahoo, Bing and Wikipedia, but also makes use of its own web crawler called DuckDuckBot. It also includes a knowledge panel that shows important information such as contacts or statistics. The information is retrieved from Wikipedia and Yelp, which stores reviews from users for products.
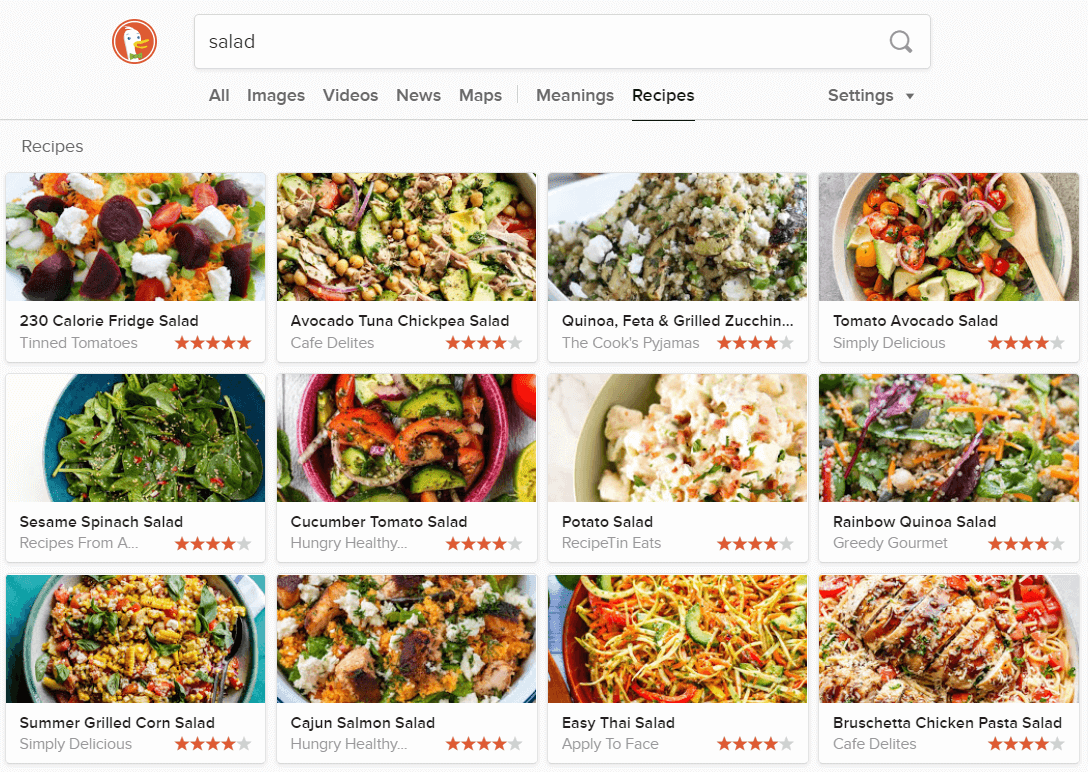
DuckDuckGo also contains features that are different from Google. It uses dynamic vertical-search. For example, when typing a query related to food, it dynamically opens up a new category for ‘recipes’. DuckDuckGo is capable of understanding the semantic of queries and can decipher the best category to use.
3. CC Search
Search for copyright-free images.
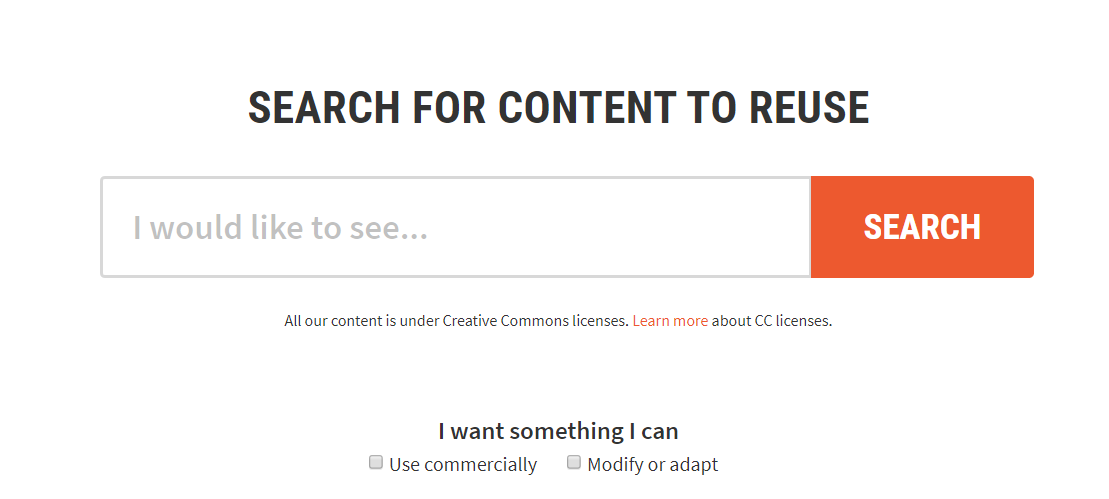
If you are a content writer, CC Search is your best bet to finding copyright-free images. It extracts images from sources like Flickr, DeviantArt, Wikimedia, and several online art museums.
It only selects media that have a license labelled Creative Commons. A Creative Commons (CC) license is a type of public copyright license that enables the free distribution of the author’s work. The author gives the right to the public to share, use or add to it.

You can refine the images further by making use of a number of the filters (as seen on the left panel). Filters can ensure you retrieve the exact dimensions and type that you require.
4. The Wayback Machine
Search through snapshots of web pages across time
Founders of Alexa, later becoming part of Amazon, Brewster Kahleand & Bruce Gilliat created The Wayback Machine back in 1996. The Wayback Machine is a digital archive of internet content, containing a timeline of snapshots of web pages.
From time to time, websites are archived, leaving behind a snapshot that can be later retrieved. Apart from auto-backups of snapshots, users can choose to upload a webpage to the WayBack Machine for storing.
Wayback Machine uses web-crawling software to obtain the content collected in its repository. The crawler distinguishes the domain, retrieved by Alexa, and uses a series of rules to categorise and retrieve the content.
Limitations of crawling
Websites may contain a robot text file which indicates which pages not to index. If the web page does not allow crawling, the Wayback Machine does not index the content for the domain.
The webpages are only viewed as HTML files because the content is extracted from their stored servers. Only internal pages linked inside the content are followed by the search engine. Dynamic web pages may contain missing content as crawling might not be able to retrieve all software code, like those retrieved through scripts, images and other files. Therefore, the Wayback Machine is more of a catalogue of standard HTML pages.
A potential for webmasters
As mentioned in one of our earlier blogs, Wayback Machine can be used to discover expired domains that may have high domain authority backlinks. For more information, click here.
5. Google Reverse Image Search
Retrieve information through image search
Have you ever went out trekking and wondered what a certain plant was called? Or you saw a wallpaper of beautiful scenery and wondered where it is? Google Reverse Image Search can do just that. Rather than searching with keywords to find an image, Google reverses the process by allowing the user to upload or link any image. The results will show the relevant keywords and a list of similar images.
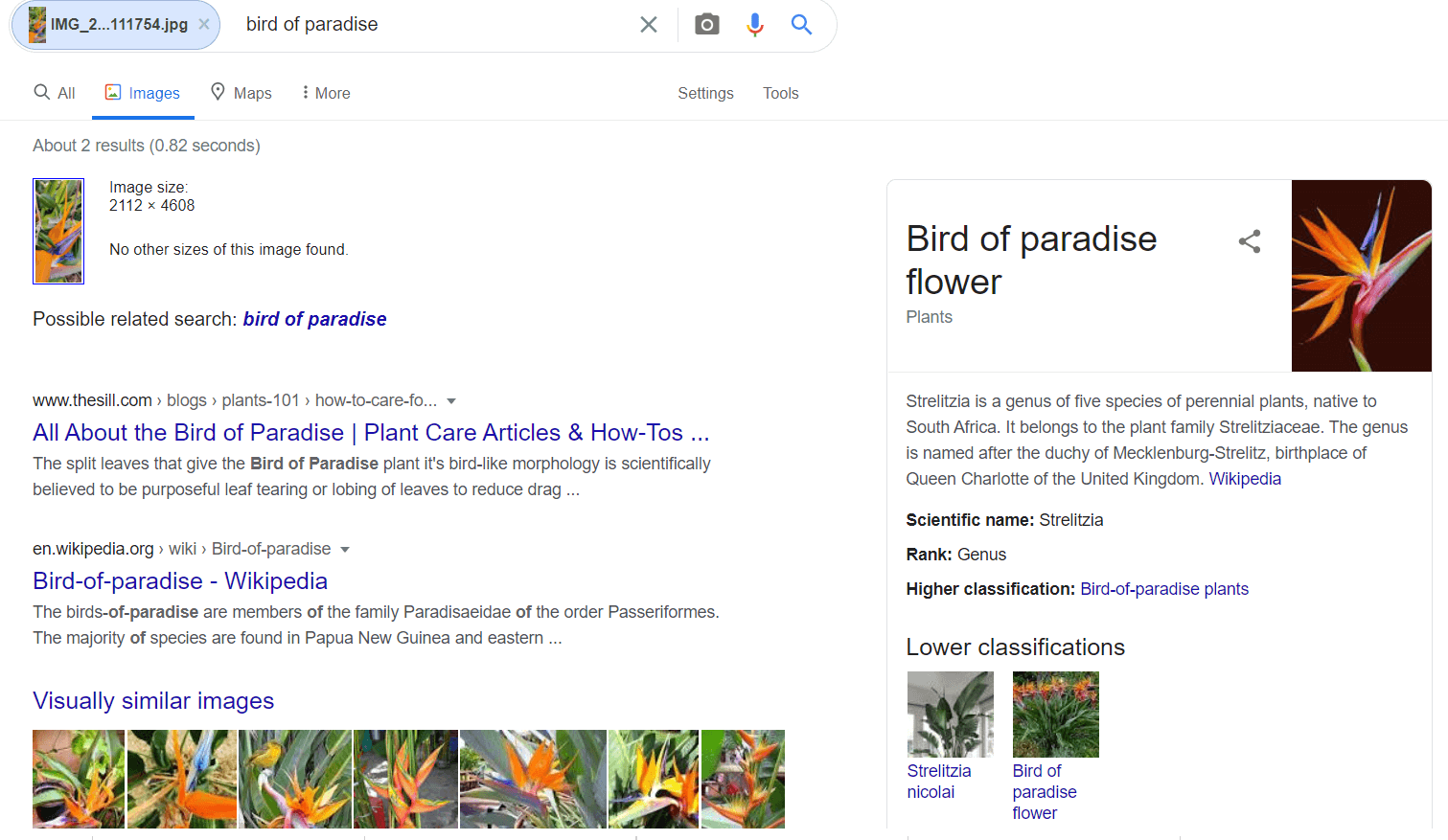
For example, I uploaded an image of a plant I saw while hiking. Google showed me exactly the name of the plant, as well as a knowledge panel indicating the classification of the plant.
Apart from giving you detailed information, Google Reverse Image search can also help you find an image’s original source and track any copyright violations.
Final Thoughts and Considerations
It is time we stop thinking about search engines as only a list of webpages that are relevant. We are at a time when we need quick direct information presented in a clear way without affecting our privacy rights. All these search engines have something that makes them distinct from traditional search engines. They all provide a unique feature that is worth looking into.
At Gainchanger we automate the tedious part of SEO to allow you to scale your results exponentially and focus on what really matters.
Get in touch for a free 5-minute consultation or to start scaling your strategies today.
