
Over the years Google has improved its way of understanding the category and quality of a web site. This was achieved through machine learning algorithms that understand the nature of the content and its quality. In this article we will cover the basics of Natural Language Processing and how you can leverage Google NLP for your SEO strategy
What is NLP?
NLP is a sub-field of artificial intelligence which focuses on the interpretation of text data produced by humans. More specifically, NLP is concerned with the programming of computers to decipher, analyse and produce natural language data such as in text format. Such data is referred to as unstructured data as it cannot directly be stored into a tabular format, for example a table. NLP therefore focuses on converting unstructured data to a structured format with the aim of quantifying the quality and originality of the content.
NLP algorithms are unable to read text in the same way humans do, therefore it searches for patterns within the text. The first step towards pattern identification is to eliminate unimportant words such as conjunctions (“however”, “but”, “so” etc…) and articles (“a”, “the” etc…). Other words deemed irrelevant to the task at hand are also eliminated at the discretion of the programmer. The next step is to divide each sentence into smaller chunks of words or characters, known as tokens. The occurrence of each token is then counted and the token together with its frequency of occurrence is stored in a table. This is the most fundamental step of NLP and is referred to as Natural Language Understanding (NLU) as it aims to extract meaning from text. Most algorithms go beyond this basic approach by applying machine learning algorithms to understand the position and grammatical function of each token, together with its linguistic dependence. Using this information, NLP algorithms assign a saliency score to each token, as well as the entire article, and hence gauges the quality and originality of the content. In addition to this, the specific tokens appearing in a sentence can indicate the sentiment conveyed. Sentiment is calculated incrementally, such that multiple positive tokens surrounded by neutral tokens indicate a very positive sentiment, whilst positive tokens appearing together with negative tokens will convey an overall neutral sentiment.
Unstructured data makes up to 79% of all online data, and is constantly being generated as people communicate on Facebook, Twitter, Messenger, Reddit, Whatsapp etc…Only human intelligence can fully comprehend the meaning of such data, however by using NLP to analyse this data, businesses can better understand their customers in an automated and scalable manner. More importantly, businesses can harness the information obtained through NLP in order to boost their Google rankings.
Although the coding required to carry out such a task may seem daunting, one needn’t learn about the underlying machine-learning algorithms or how to code in Python – the Google Natural Language API will do all the dirty work for you.
What is Google NLP API ?
The Google Natural Language API is an application program interface (REST API) available on the Google Cloud Platform which applies machine learning algorithms to extract information and derive insights from any text data input. The API is free and extremely easy to use. Furthermore, the API is based on the machine learning algorithms used in Google’s own search algorithms. The algorithms can be called as “black-box” functions, meaning that the underlying machine algorithms are hidden from the user and are composed of complex deep learning models. A generic example for sentiment analysis is shown below.
The best way to understand the benefits of the Google NLP API is to see it in action. This can be done by using the Natural Language API demo found here. For this example we shall analyse three sentences of text from the Wikipedia page on Online Poker.
Step 1: Open the Wikipedia page on your topic of interest.
Step 2: Open the Google Cloud Natural Language API demo.
Step 3: Copy and paste the text from the Wikipedia article to the text entry window and click “ANALYZE”.

Using the Google NLP API demo is extremely simple. It provides four types of analysis: Entity Analysis, Sentiment Analysis, Syntax Analysis and Category Analysis. Let us explore each of the four functionalities:
Google Cloud NLP Entity Analysis
The entity analysis functionality of the Google Cloud NLP API uses machine learning to identify tokens within an article or paragraph which are or contain points of interest. The input text is analysed to identify proper nouns (celebrity names, company names etc…) and common nouns (generic locations ex. casino) within the text, referred to as entities. The API then returns a score to each entity, referred to as a “saliency” score. The salience of an entity is a metric that quantifies its significance within the text in relation to other surrounding words, and is Google’s attempt at predicting the importance of this entity to future readers of this specific paragraph or article. The saliency score is calculated by carrying out syntax analysis which aims to identify the grammatical role of each token in a sentence as well as its frequency of occurrence. The use of other tokens to refer to an entity are also considered by the algorithm, for example an instance of the word “it” referring to the token “card room” is counted as an additional occurrence of the token “card room”. The function used to perform this analysis is the analyzeEntities method.
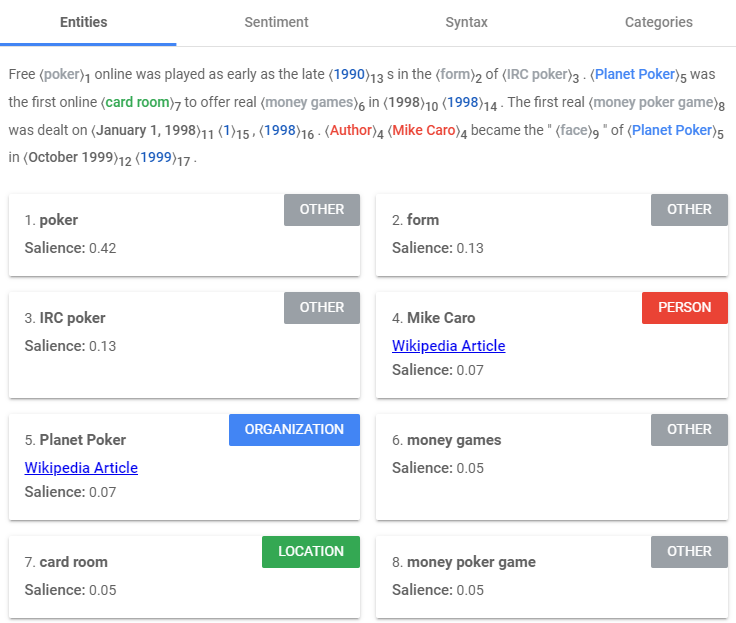
Google’s NLP algorithm has clearly identified that the most important entity in this chunk of text is the word “poker”, as reflected by its salience score. The algorithm has also deemed the entities “form” and “IRC poker” as nearly twice as salient as “Mike Caro” and “Planet Poker”. This could be perhaps because the former tokens appear less frequently in related chunks of texts than the latter tokens, deeming the content of this text unique.
Google Cloud NLP Sentiment Analysis
The sentiment analysis functionality identifies the most dominant sentiment of the text, that is whether the emotion conveyed by the writer is positive, negative, or neutral. In command line, the API functions related to sentiment analysis are in the form of a black box which can be called for individual sentences or whole paragraphs and returns two outputs: a Sentiment score and a Magnitude score. The Sentiment score indicates the overall sentiment of a token, sentence or paragraph and can range between -1 and 1, where values between -1 and -0.25 indicate negative sentiment, values between -0.25 and 0.25 indicate neutrality, and values between 0.25 and 1 indicate positive sentiment. The Magnitude score can range between 0 and infinity (+inf) and quantifies the overall strength of positive or negative emotion. This score is dependent on the number of positive or negative words in each sentence or paragraph, for example, sentences/paragraphs containing many positive or negative tokens will result in a higher Magnitude score. Longer text blocks may consequentially result in greater magnitudes since they will most likely contain more words with non-zero sentiment scores.
As shown below, the Google NLP API is applied to sentences/paragraphs as well as the individual entities identified in the previous step. The former is performed by the function analyzeSentiment whilst the latter is performed by the function analyzeEntitySentiment which can both be called in command line or a s part of a larger programme.
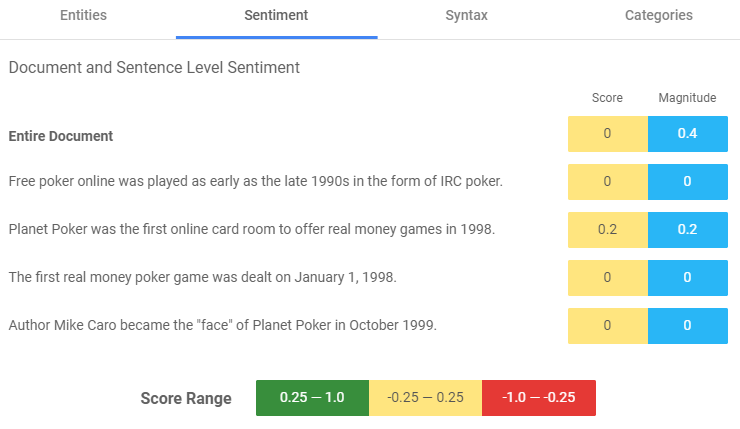
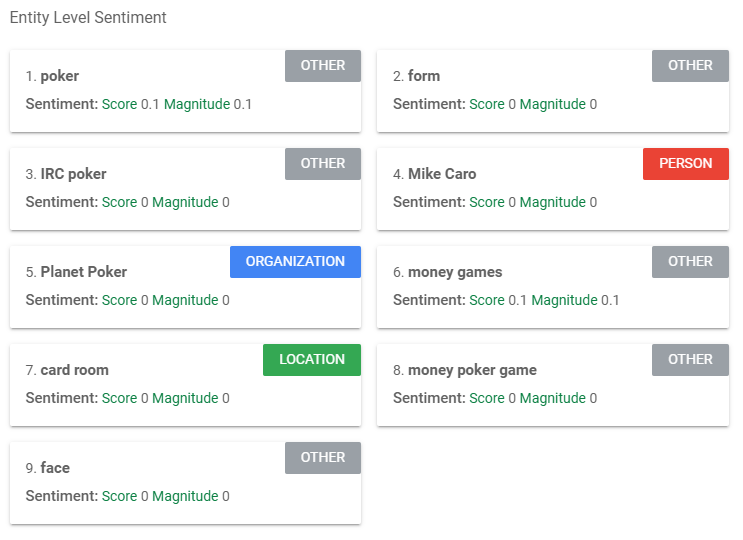
Google Cloud NLP Syntax Analysis
The black box function analyzeSyntax analyses the tokens to extract linguistic information from the text. It does this by identifying the role of each token within the sentence/paragraph.
The details provided by this function relate to the dependency of individual words within a sentence, the parse label (contextual role of ach word/token), part of speech (noun, verb, adverb, adjective etc…), lemmatization (lemma/root word identification) and morphology (conjugation of the lemma/root word). The syntactic analysis that Google has created to analyse text in this manner is extremely complex and the other aforementioned functionalities mostly stem from this base function (such as entity analysis and calculation of entity salience). This function also shows us how Google’s ranking algorithms identify grammatical errors within a sentence/paragraph. Additionally, the Syntax Analysis algorithm shows us what Google deems as the focus (root) of each sentence, and therefore allows us to change sentences appropriately to convey the correct root of our text.
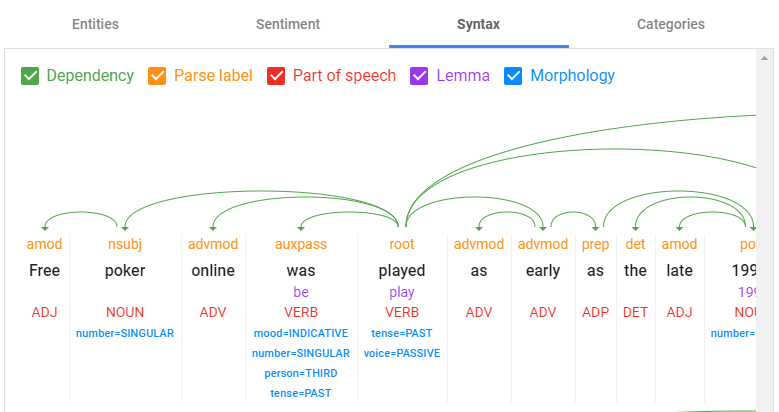
Google Cloud NLP Category Analysis
Using the classifyText function, the Google NLP API analyses text content and returns a content category for the content. This function is carried out using a machine-learning classification model which is pre-trained on chunks of text which are already classified into categories. The machine-learning model analyses the input text and identifies tokens and patterns within the data that have already been exhibited in other texts during the training phase. The algorithm generates a Confidence Score for various categories and will show to screen the categories with the highest Confidence Score. The Confidence Score defines how confident the algorithm is at classifying the input text into the corresponding category.
It is worth noting that each API automatically detects the language used, even if this is not specified by the caller upon calling the function. Additionally, the above functions can all be performed by a single API call to the function annotateText.
How to leverage Google NLP for SEO
Now that we have understood the basics of Google NLP, we can now have a look at its significance in relation to SEO. An important thing to remember when using Google NLP to boost your SEO efforts is that Google uses the same algorithms to gauge the relevance of your webpage’s content to keyword searches. This is evident in the top ranking pages following a search for the keyword “online poker”.
Let us have a look at the top two ranking pages which are not paid ads:
The first chunk of text on the landing page for PokerStars is as follows:

The wording in this paragraph is not a coincidence and has been carefully selected to maximise ranking potential. This is evident by carrying out Google NLP analysis on this paragraph, resulting in the following entity, sentiment, and category analyses:
Entity analysis
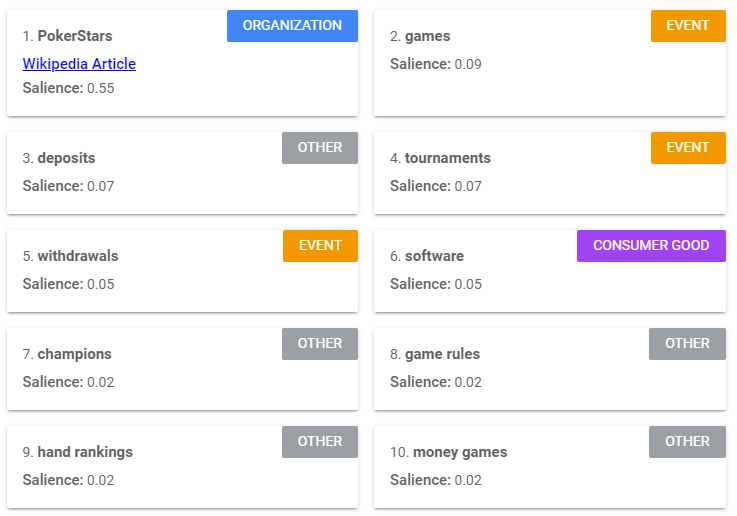
The entity analysis has identified PokerStars as the most salient entity and has correctly defined this entity as an organisation. Other identified entities include the tokens “games”, “deposits”, “tournaments”, “withdrawals” and “software”. Although the saliency is much lower, these tokens are highly relevant to keywords that are of interest to PokerStars.
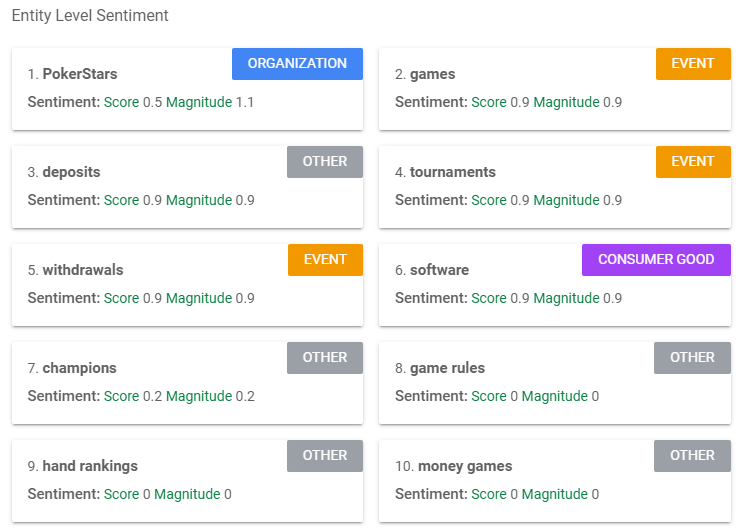
Sentiment analysis
The sentiment perceived by Google’s NLP algorithm is an overall positive one with a comparatively high magnitude. The use of the tokens “safe”, “fast”, “award-winning”, “champions” and “better” in each respective sentence undoubtedly contribute to this. This is a clear example of how descriptive text can improve the overall sentiment conveyed by a chunk of text and can improve your chances of ranking highly in relation to specific long-tail keywords which are descriptive. For example, PokerStars is definitely positioning itself to rank highly for Google searches of positive keywords such as “best online casino” as they have already conveyed positive sentiment in their website’s landing page.

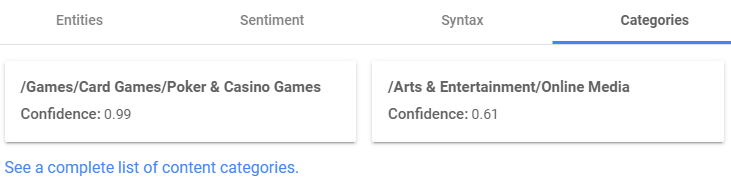
Category analysis
For the online gambling industry, it is a good idea to ensure that your text ensures that Google classifies you into the two categories exhibited below (and scores highly within each category), as PokerStars has done. This increases your chances of ranking highly following a search for “online casino” as your text indicates that your content matches both the “casino” industry as well as the “online entertainment” industry. Although this approach may not be applicable for very niche industries, it certainly seems to be ideal for the online gambling one.

The first chunk of text on the landing page of www.partypoker.com is as follows:

One of the reasons why PartyPoker ranks after PokerStars in an online search for online casino can be seen below in the Google NLP entity, sentiment, and category analyses for their landing page:
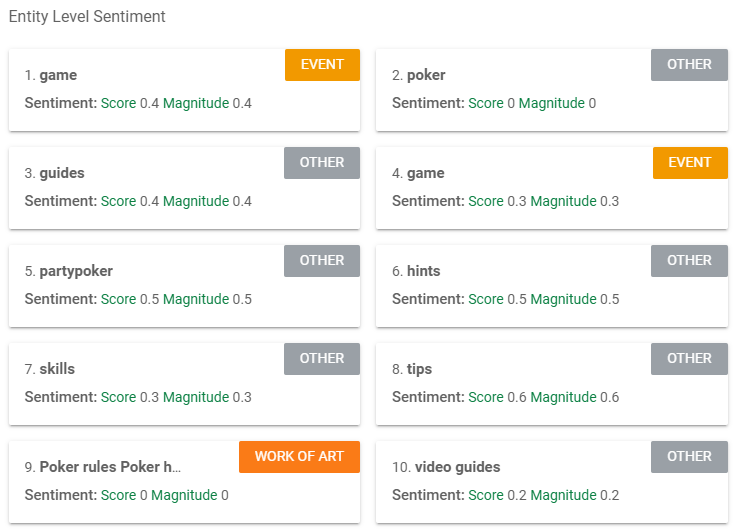
Entity analysis
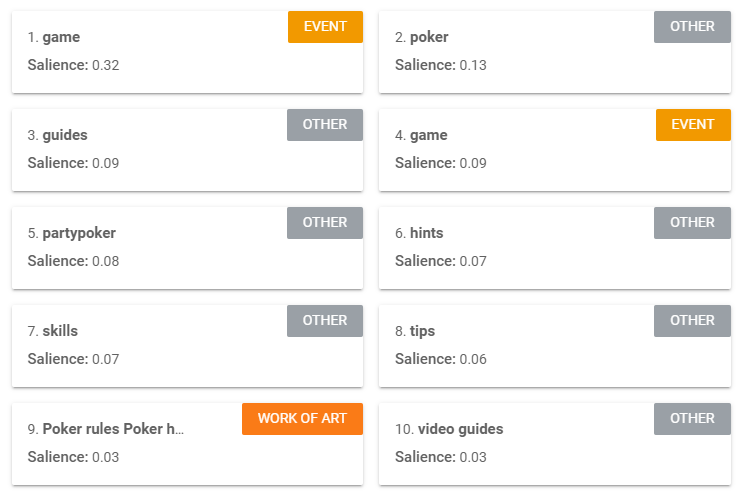
The chosen entities, or points of focus, expressed in the first paragraph differ greatly from that of PokerStars. PartyPoker started off well by focussing on the entities “game”, “guide”, “software”, “rules”, “hints”, “skills” which overall scored slightly higher in saliency than the entities in the previous PokerStars analysis (apart from the entity PokerStars which scored extremely high in saliency).
Sentiment analysis
The sentiment analysis reveals that the overall Sentiment Score was as high as that of PokerStars but the Magnitude was much lower (2.4 for PokerStars and 0.9 for PartyPoker). This could have been increased by using more positive descriptive words in the text and perhaps opting for sentences to allow this as opposed to text in point form, as the Google NLP API perceived the text in point form as an entire sentence as opposed to separate exclusive points. This is important as the text in point form above is not descriptive enough and the writer has missed out on the opportunity of enriching the entities occurring in the bullet points with descriptive words that convey positive sentiment. Once again, this is important because the algorithms used in the Google NLP API are the same ones used in the Google search ranking algorithms.

Category analysis
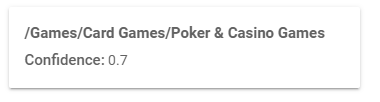
The write of the PartyPoker landing page has missed out on the opportunity of this text falling under the category of “Online Entertainment” the rules required to ensure that text falls under this category is unknown as the category classification is carried out by a black box machine-learning algorithm. Ensuring one’s text falls under the desired category is a game of trial and error at this point (until more is learnt about Google’s NLP APIs), however it can only help to use more descriptive words (the word “online” does not feature in this text) and calls for action (such as the words “enjoy”, “discover” and “practice”) can ensure that the Google NLP API understands that online games can be played on your site and it is not simply a page for sharing “tips”, “hints” and “brush[ing] up skills”.
Limitations of Google NLP
Overall the Google NLP APIs are valuable online tools that can be used to improve your website content and provide insight into the backend algorithms used in Google search ranking. The algorithms however are not infallible and it is evident from the demo that they are limited to individual sentences or short paragraphs of text and do not adapt well to large chunks of text or text in point form. When a longer chunk of text is used as input the usefulness of this tool is significantly reduced. This is evident by the number of times the same word shows up as different entities, for example the word “game” in the PartyPoker analysis. Nonetheless, this limitation is somewhat insightful as it shows us that the Google NLP algorithm considers the phrases “game” and “money games” as two mutually exclusive entities.
Nonetheless the Google NLP demo is a useful tool to analyse short chunks of text, such as meta descriptions, service descriptions, introductions etc…as it shows us how Google perceives our webpages prior to publication and allows us to make informed changes to ensure that Google “understands” the scope and focus of our text on a webpage. The same can be applied to longer articles of text, however they must be broken down into smaller chunks of text to fully grasp how Google’s algorithms perceive your webpage text.
The Google NLP algorithm does not provide us with clear information on the link between keywords and entity salience. For this reason, it is not ideal to replace keywords with highly salient entities from webpage text. It does however provide us with an indication of whether our text is SEO-friendly and whether the focus of our text is being picked up by the Google algorithms.
As things stand, the Google NLP demo or the Google Cloud Natural Language Products cannot be easily scaled to analyse large data inputs, however they set a good precedent for further research in this field and one can expect that the algorithms will become more insightful, scalable and user-friendly with time.

Dr Michaela Spiteri BEng, MSc, PhD (AI / Healthcare domain), is a well-published researcher in the field of AI and machine-learning. She is the founder of AI consultancy Analitigo Ltd. Currently working as the lead researcher at Gainchanger.
